
Prev: Getting started with RKH
Next: Using submachine states
Run-to-completation execution model
Event occurrences are detected, dispatched, and then processed by the state machine, one at a time. The order of dequeuing is not defined, leaving open the possibility of modeling different priority-based schemes. The semantics of event occurrence processing is based on the run-to-completion assumption, interpreted as run-to-completion (RTC) processing. Run-to-completion processing means that an event occurrence can only be taken from the pool and dispatched if the processing of the previous current occurrence is fully completed.
The processing of a single event occurrence by a state machine is known as a run-to-completion step. An RTC step is the period of time in which events are accepted and acted upon. Processing an event always completes within a single model step, including exiting the source state, executing any associated actions, and entering the target state. Before commencing on a run-to-completion step, a state machine is in a stable state configuration with all entry/exit/internal activities (but not necessarily state (do) activities) completed. The same conditions apply after the run-to-completion step is completed. Thus, an event occurrence will never be processed while the state machine is in some intermediate and inconsistent situation. The run-to-completion step is the passage between two state configurations of the state machine. The run-to-completion assumption simplifies the transition function of the state machine, since concurrency conflicts are avoided during the processing of event, allowing the state machine to safely complete its run-to-completion step.
When an event occurrence is detected and dispatched, it may result in one or more transitions being enabled for firing. If no transition is enabled and the event (type) is not in the deferred event list of the current state configuration, the event occurrence is discarded and the run-to-completion step is completed. During a transition, a number of actions may be executed. If such an action is a synchronous operation invocation on an object executing a state machine, then the transition step is not completed until the invoked object completes its run-to-completion step.
The RKH implementation preserves the transition sequence imposed by Harel's Statechart and UML. Specifically, the implemented transition sequence is as follows:
- Execute exit actions of the source state.
- Execute the transition actions.
- Execute entry actions of the target state.
Run-to-completion may be implemented in various ways. The most common way to do that is by an event-loop running in its own thread, and that reads event occurrences from a pool as sketched in the following figure.
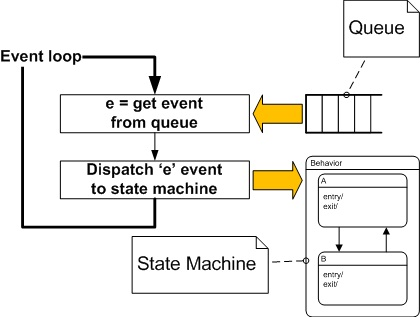
In case of active objects or SMA (State Machine Application), where each object has its own thread of execution, it is very important to clearly distinguish the notion of run-to-completion from the concept of thread pre-emption. Namely, run-to-completion event handling is performed by a thread that, in principle, can be pre-empted and its execution suspended in favor of another thread executing on the same processing node. (This is determined by the scheduling policy of the underlying thread environment, no assumptions are made about this policy.). When the suspended thread is assigned processor time again, it resumes its event processing from the point of pre-emption and, eventually, completes its event processing.
An active object is an object that, as a direct consequence of its creation, commences to execute its behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as "the object having its own thread of control"). An active object encapsulates a thread of control (event loop), a private event queue, and a state machine. So, Active object = thread of control + event queue + state machine.
Preemptive Kernel
In the most common and traditional implementations of the active object computing model, active objects map to threads of a traditional preemptive RTOS or OS. In this standard configuration the active object computing model can take full advantage of the underlying RTOS capabilities. In particular, if the kernel is preemptive, the active object system achieves exactly the same optimal task-level response as traditional tasks.
In this approach, RTC semantics of state machine execution do not mean that a state machine has to monopolize the CPU for the duration of the RTC step. A preemptive kernel can perform a context switch in the middle of the long RTC step to allow a higher-priority active object to run. As long as the active objects don't share resources, they can run concurrently and complete their RTC steps independently.
The Figure 15 shows the events flow in a interval of time to state machines A, B, and C, which have priority 2, 1 and 3, respectively. Note that, the lower the number the higher the priority. Moreover, the Figure 16 and Figure 17 are considered to illustrate how the preemptive kernel and cooperative kernel plays out in an active object system like Figure 15.
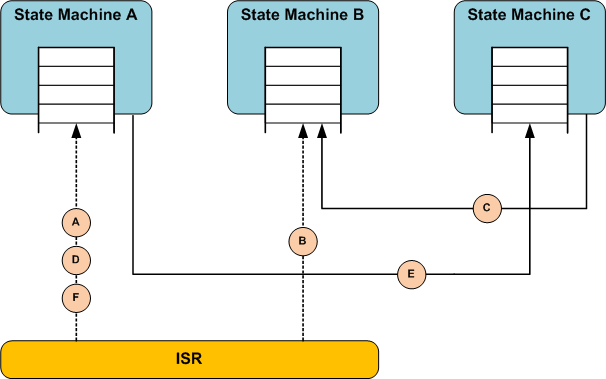
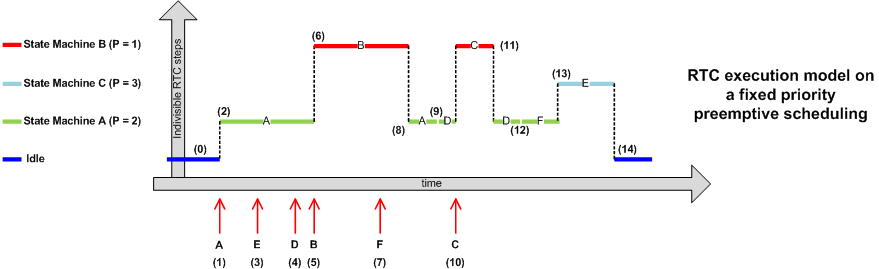
Figure 16 demonstrates how the active objects defined on the Figure 15 would be scheduled by a underlying preemptive kernel for executing event-driven system despicted in Figure 15.
The following explanation section illuminates the interesting points:
- (0) When all event queues run out of events, neither of three active objects are able to run, the underlying kernel executes the idle task to give the application a chance to switch the MCU to a low-power sleep mode.
- (1) The ISR executes and, among other things, posts event A to the active object A, which is now able to execute. It has a higher priority than the OS/RTOS idle task so is given processor time.
- (2) The preemptive kernel switches context to the active object A to process the event to completation.
- (3) While active object A is still executing, the ISR posts the event E to active object C, which is now able to execute, but as it has a lower priority than active object A it is not scheduled any processor time.
- (4) Once again, while active object A is still executing, the ISR posts the event D to active object A, but it is already running the event is not processed, thus respecting the RTC execution model.
- (5-6) The ISR executes and posts event B to the active object B, which is now able to execute. Now it is able to execute. As B has the higher priority A is suspended before it has completed processing the event, and B is scheduled processor time.
- (7) Idem (3).
- (8) The active object B has been completed the event processing. It cannot continue until another event has been received so suspends itself and the active object A is again the highest priority active object that is able to run so is scheduled processor time so the event A processing can be resumed.
- (9) The active object A has been completed the event processing, and A is again the highest priority active object that is able to run so is scheduled processor time so the event D processing can be completed.
- (10) Idem (5) and (6).
- (11) Idem (8).
- (12) Idem (9).
- (13) Idem (11).
- (14) Idem (0).
Simple cooperative kernel
The active object computing model can also work with nonpreemptive kernels. In fact, one particular cooperative kernel matches the active object computing model exceptionally well and can be implemented in an absolutely portable manner.
The simple nonpreemptive native kernel executes one active object at a time in the infinite loop (similar to the "superloop"). The native kernel is engaged after each event is processed in the RTC fashion to choose the next highest-priority active object ready to process the next event. The native scheduler is cooperative, which means that all active objects cooperate to share a single CPU and implicitly yield to each other after every RTC step. The kernel is nonpreemptive, meaning that every active object must completely process an event before any other active object can start processing another event.
The ISRs can preempt the execution of active objects at any time, but due to the simplistic nature of the native kernel, every ISR returns to exactly the preemption point. If the ISR posts an event to any active object, the processing of this event won't start until the current RTC step completes. The maximum time an event for the highest-priority active object can be delayed this way is called the task-level response. With the nonpreemptive native kernel, the task-level response is equal to the longest RTC step of all active objects in the system. Note that the task-level response of the native kernel is still a lot better than the traditional "superloop" (a.k.a. main+ISRs) architecture.
The task-level response of the simple native kernel turns out to be adequate for surprisingly many applications because state machines by nature handle events quickly without a need to busy-wait for events. (A state machine simply runs to completion and becomes dormant until another event arrives.) Also note that often you can make the task-level response as fast as you need by breaking up longer RTC steps into shorter ones. [MS]
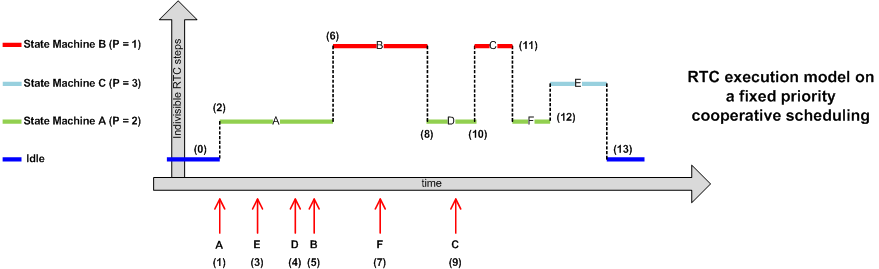
Figure 17 demonstrates how the active objects defined on the Figure 15 would be scheduled by a simple, cooperative, and non-preemptive kernel for executing event-driven system despicted in Figure 15.
The following explanation section illuminates the interesting points:
- (0) When all event queues run out of events, neither of three active objects are able to run, the underlying kernel executes the idle task to give the application a chance to switch the MCU to a low-power sleep mode.
- (1) The ISR executes and, among other things, posts event A to the active object A, which is now able to execute. It has a higher priority than the OS/RTOS idle task so is given processor time.
- (2) The preemptive kernel switches context to the active object A to process the event to completation.
- (3,4,5) While active object A is still executing, the ISR posts the events E, D and B to active objects C and B, which are now able to execute, but as the underlying kernel is non-preemtive one active object A it is not scheduled any processor time until it has completed the current execution.
- (6) The active object A has been completed the event processing. The active object B is the highest priority active object that is able to run so is scheduled processor time until is has completed the processing of event B in a RTC manner.
- (7) Idem (3,4,5).
- (8) Idem (6).
- (9) Idem (3,4,5).
- (10,11,12,13) Idem (6).
Dealing with RTC model in a nonpreemtive manner
Here is the basic algorithm for interpreting the native kernel. The rkh_fwk_enter() function implemented in source/fwk/src/rkhfwk_sched.c source file is self-explanatory.
Application-specific and port dependencies
First of all, pay special attention to Porting and Installation sections and then following the win32 single thread demo and its own port from the directories demo/80x86/<example>/build/win32_st/vc and /source/portable/80x86/win32_st/vc/ respectively. The main goal to this is to make it easy to understand the event-driven code and experiment with it.
Main function
As said above, following the win32 single thread demo and its own port from the directories demo/80x86/<example>/build/win32_st/vc and source/portable/80x86/win32_st/vc respectively. However, the main() function is shown below to illustrate the RKH concept.
Prev: Getting started with RKH
Next: Using submachine states